Computer Vision
Meta
Datasets
- ImageNet
- COCO
Vision tasks
| Task | Variations |
|---|---|
| Object detection | Real time, non-realtime, rotated, captioning, classification |
| Object tracking(video) | Similar to object detection but with some additional checks |
| Segmentation | SAM2 etc. |
| Contrastive Learning | |
| Distillation | |
| VDU (Visual Document Understanding) | OCR, OCR-free |
| VQA (Visual QA) | |
| Pose estimation |
Image generation
Object Detection
| Architecture | Type | Name | Use | Other notes |
|---|---|---|---|---|
| Transformer | VLM | LLaVA | Visual Q/A, alternative to GPT-4V | |
| VLM | moondream | same as LLaVa | can’t do ocr probably | |
| VLM | CogVLM | same as LLaVa | Better than LLaVa in captioning | |
| ViT | CLIP | txt-guided imagen, classification, caption | ||
| ViT | BLIP | Same as CLIP, better than CLIP at captioning | Considered faster than CLIP? | |
| ViT | DETIC | |||
| ViT | GDINO | Better at detection than CLIP | similar to YOLO but slower | |
| CNN | 1 stage | YOLO | Realtime object identification | No involvement of anything NLP like VLMs |
| 2 stage | Detectron-2 | Apache license, Fast-RCNN | ||
| EfficientNetV2 | classification |
- See Image Compression for ideas around perceptual hashing.
Theory
- What are some foundational papers in CV that every newcomer should read? : computervision
- Object Detection | Papers With Code
- A Dive into Vision-Language Models
- Closed-set: Detect from trained stuff. Eg. Find all dogs in the image
- Open-set: Detects un-trained stuff. Eg. Find the right-most dog, is a person holding a dog? (Transformer based work nicely here)
- In other words, allows to do
zero-shotobject detection
- In other words, allows to do
CNN based
- CNN uses pixel arrays
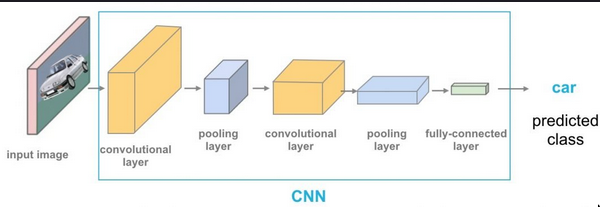
-
YOLO! (?)
- https://roboflow.github.io/model-leaderboard/
- Show HN: Using YOLO to Detect Office Chairs in 40M Hotel Photos | Hacker News
Lot of crazy politics. anyone is coming up with anything. The newer version doesn’t mean the newer version of the same thing. superr confusing. Original author left the chat long back cuz ethical reasons
“The YOLOv5, YOLOv6, and YOLOv7 teams all say their versions are faster and more accurate than the rest, and for what it’s worth, the teams for v4 and v7 overlap, and the implementation for v7 is based on v5. At the end of the day, the only benchmarks that really matter to us are ones using our data and hardware”
- YOLO algorithm treats object detection as a regression problem, utilizing a single convolutional neural network to spatially separate bounding boxes and associate probabilities with detected objects.
- YOLO is a family of detection algorithms made by, at times, totally different groups of people.
- See Programming Comments - Darknet FAQ
- See [2304.00501] A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS
Year Name Description Darknet/YOLO Someone says it’s faster than the newer version, idk tf they talking about. Goes upto YOLOv7 2015 YOLOv1 Improved on R-CNN/ Fast R-CNN by doing 1 CNN archtecture, made things real fast 2016 YOLOv2 Improved on v1 (Darknet-19), anchor boxes 2018 YOLOv3 Improved on v2 (Darknet-53), NMS was added YOLOv4 Added CSPNet, k-means, GHM loss etc. YOLOv5 YOLOv6 YOLOv7 YOLOv8 YOLOv8-n YOLOv8-s YOLOv8-m YOLOv10 YOLO-X Based on YOLOv3 but adds features as anchor free and other things. YOLO NAS for detecting small objects, suitable for edge devices YOLO-World 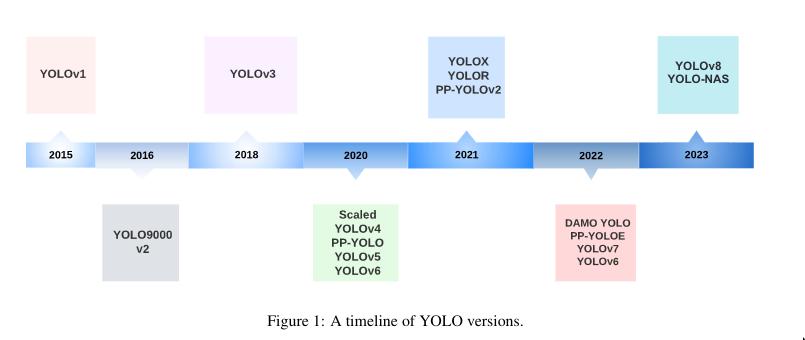
-
YOLO vs older CNN based models
From a reddit comment
- the R-CNN family:
- Find the interesting regions
- For every interesting region: What object is in the region?
- Remove overlapping and low score detections
- YOLO/SSD:
- Come up with a fixed grid of regions
- Predict N objects in every region all at once
- same as above
- the R-CNN family:
-
MMLabs 🌟
- mmdetection (MMLabs)
- More like a framework for vision models.
- Good choice if you’re just experimenting with a model right now. The SOTA model can be trained via config alone.
- Has both CNN and Transformer based stuff
- It also has YOLO model variants: https://github.com/open-mmlab/mmyolo
-
Doubts
- ResNet?
Transformer (Vision Encoder, ViT)
See VLM(Vision Language Models)
- Main pupose: extract visual features into embeddings
- ViT splits the input images into visual tokens
- divides an image into fixed-size patches
- correctly embeds each of them
- includes positional embedding as an input to the transformer encoder
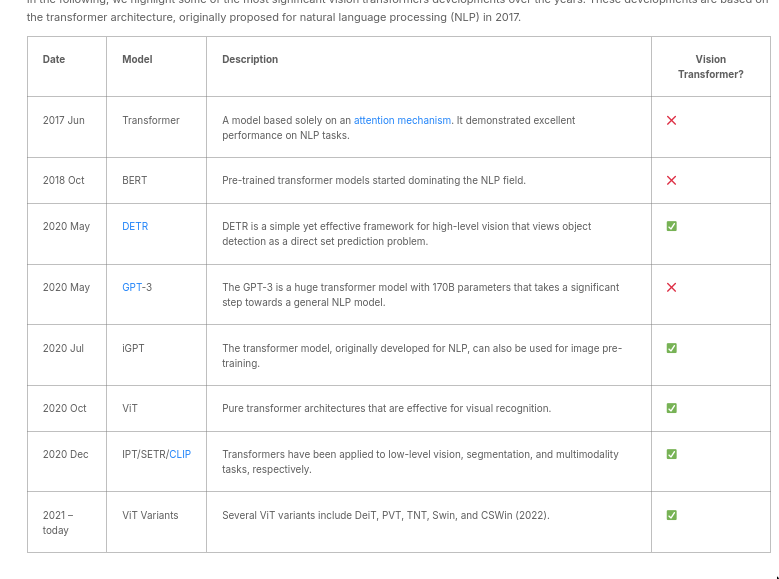
- The OG here is ViT
(Google Brain team)
- Downstream variants include: BEiT, DeiT, Swin, CSWIn(better than Swin), MAE, DINO(Improved DETR)
- Prior work before ViT was DETR
- Has outperformed CNN models in certain cases
- ViT models outperform the current SOTA CNNs by almost x4 in terms of computational efficiency and accuracy.
- Examples of implementation: CLIP, GDINO
- ViT is what CLIP uses. In other words, CLIP is possible because of ViT.
- GroundingDINO(GDINO)
uses DINO
- Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs - YouTube (combining DINO+CLIP for better results)
- this blogpost has simple explanation of the architecture
Combining Transformer based + CNN based
This is only useful if you need super fast inference, low on compute inference etc. Otherwise for most cases GDINO/CLIP etc goto.
- Now CNN based inference is faster than transformer based. So something like YOLO is still more preferable for realtime stuff.
- But we can use GDINO to generate label for our training dataset and then we can use this to train our YOLO models which will be fast.
- Essentially, use Transformer based detection for labeling & training the CNN model
- Use the CNN model to do fast inference in production
- Basically using foundation models to train fine-tuned models. The foundation model acts as an automatic labeling tool, then you can use that model to get your dataset.
- https://github.com/autodistill/autodistill allows to do exactly this.
- see https://www.youtube.com/@Roboflow/videos
Segmentation
| Name | Description |
|---|---|
| SEEM | |
| SAM |
- To improve segmentation we can tune the params, else we can also use some kind of object detection(eg. yolo etc) to draw bounding boxes before we apply segmentation to it. See this thread for more info.
Visual Document Understanding (VDU)
- OCR
- 2-stage pipeline: Usually when trying to understand a document, we’d do OCR and then run though another process for the understanding.
- Issue: Mostly with OCR, the result might not be what you want. Eg. No spatial understanding ( even different line etc). Using a OCR free approach might help.
- See OCR
- OCR-free
OpenCV
VLMs
See VLM(Vision Language Models)
3D
https://news.ycombinator.com/item?id=43589989 https://github.com/VAST-AI-Research/TripoSG
Others
- It’s easier than ever to de-censor videos | Hacker News
- Traffic
- Bounding boxes