parse tree traversal?: Probably.
It gives us a way we’d traverse the tree.
Polish and Reverse Polish notation fully encode a tree structure and the steps you would take to traverse it.
While we can get a tree, we don’t really need to do that always
Because it gives a way to traverse, we can consume the output of the parser while parsing happens without generating the whole tree!
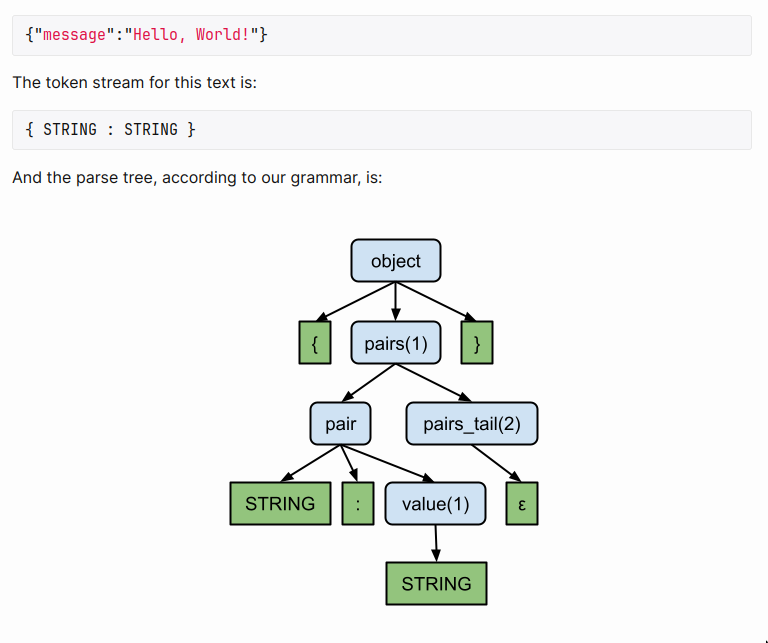
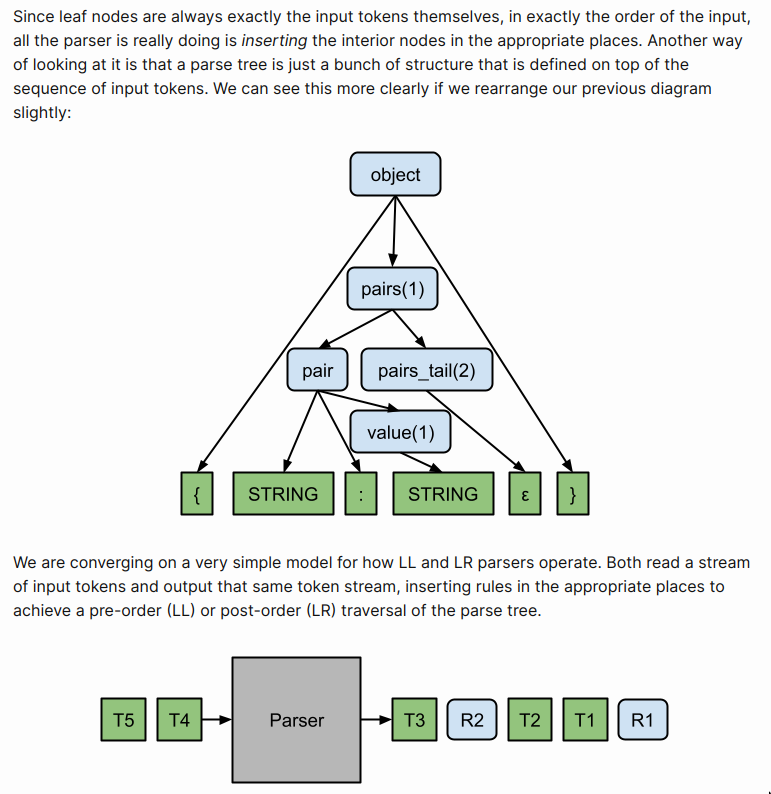
But if you think about it, the parser just adds a bunch of structure that is defined on top of the sequence of input tokens. i.e The leaf nodes are always exactly the input tokens themselves, in exactly the order of the input.
So in a very reduced manner, we can say parsers output a stream of tokens with rules added to appropriate places giving us pre/post-order traversal.
LL vs LR
LL parser outputs a pre-order traversal of the parse tree
Produces a left most derivation
Topdown
Predictive parsers
LR parser outputs a post-order traversal of the parse tree
Produces a reversed rightmost most derivation
Bottomup
Shift reducers parsers
In Practice
Not all parsers are purely based on formalism.
Usually hand-written parsers are not based on any formalism at all.
Language specifications are often defined in terms of a formalism like BNF
But it’s almost never the case that real parsers can be generated directly from this formalism.
Eg. GCC moved away from their Bison-based parser to a handwritten recursive descent parser. So did Go. While some notable language implementations do use Bison (like Ruby and PHP), many choose not to
Can produce either a postfix notation string/RPN or an abstract syntax tree (AST)
Steps
shift: add this token to the stack for later reduction
reduce: pop tokens from the stack and form a syntactic construct
end, error: no known rule applies
conflict: does not know whether to shift or reduce
Recursive Descent
Real language grammars are hardly neatly classified into LL, LR et al. Hence the vast majority of languages today use handwritten adhoc Recursive Descent parsers.
Can be directly encoded in the host language
It can parse more than CFG. TDPL grammar
can be viewed as an extremely minimalistic formal representation of a recursive descent parser
The Recursion
in “recursive descent” happens when the parser “descends” into a nested rule.
Packrat
A form of parser similar to a recursive descent parser in construction
Except during the parsing process it memoizes the intermediate results of all invocations of the mutually recursive parsing functions
Ensuring that each parsing function is only invoked at most once at a given input position
Converts input grammar into parser tables OR can be parsed recursively
LL(1)
The traditional approach to constructing or generating an LL(1) parser is to produce a parse table which encodes the possible transitions between all possible states of the parser.
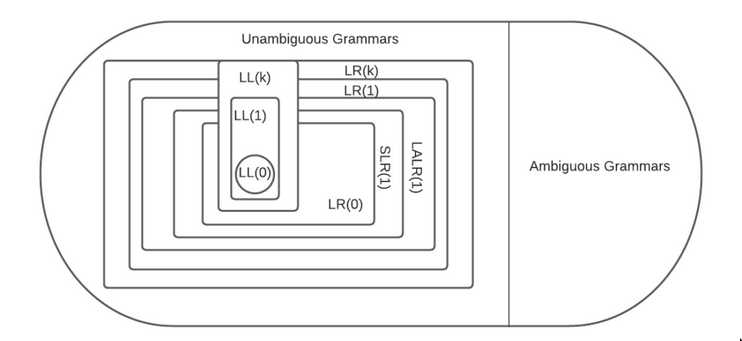
All LR(k) grammars can be mechanically transformed into LR(1) grammars, with the consequence that there are only two categories of LR languages: LR(0) and LR(1)
Converts input grammar into parser tables
Variations
Variants
Description
LALR
Look Ahead LR, Simpler than LR(1)
SLR
Simple LR, Simpler than LR(1)
CLR
Canonical LR, canonical name for the LR(1) parser
GLR
Generalized LR, Can handle ambiguous grammar
Pratt Parsing (TDOP)
Top down operator precedence (TDOP) parser
An enhancement of recursive descent parsing algorithm
Uses the natural terminology of precedence and associativity
for parsing expressions, instead of grammar obfuscation techniques.
The syntax is “abstract” in the sense that it does not represent every detail appearing in the real syntax, but rather just the structural or content-related details.
Eg. For instance, grouping parentheses are implicit in the tree structure, so these do not have to be represented as separate nodes.
An AST usually contains extra information about the program, due to the consecutive stages of analysis by the compiler.
Eg. it may store the position of each element in the source code, allowing the compiler to print useful error messages.
Since the language parsed by the parser is usually more than context-free and falls in the realm of context-sensitive
AST helps in terms of it allows you to add that context. Eg. allows new types to be declared, duck typing, operator overloading etc.
Semantic Analysis
AST is used intensively during semantic analysis, where the compiler checks for correct usage of the elements of the program and the language.
The compiler also generates symbol tables based on the AST during semantic analysis.
Parse table
Encodes the possible transitions between all possible states of the parser.
Online and Offline
online: It consumes the input tokens in a specific order and performs as much work as possible after consuming each token
Can start producing output while they are still consuming input.
Both LL and LR are online parsers because of lookahead
Predictive
Predictive parsing is parsers that do not require backtracking
Predictive parsing is possible only for the class of LL(k) grammars
Generators/Tools
Parser Generators
A parser generator reads in a grammar and spits out a parser.
It is generally not possible to combine existing grammars into a new grammar
They may be rigid in where you put the border between lexical and grammatical analysis, between grammatical and semantic one
Examples
ANTLR
ANother Tool for Language Recognition
A parser generator for efficient LL(k) parsers, where k is any fixed value.
Can generate code in more languages than Bison
ANTLR 4 deals with direct left recursion correctly
Bison
Can generate LALR(1), LR(1), IELR(1) and GLR parsers
A combinator is, classically speaking, a function which takes functions and returns functions.
Only Accepts several parsers as input and returns a new parser as its output.
Here parser is a function accepting strings as input and returning some structure as output, typically a parse tree
Parser Combinators let you build parsers easily, just by specifying the grammar.
Sometimes they let you specify the grammar in a way it looks like normal code
Sometimes they might also allow to use some special grammar notation
Eg. Parsec
FAQ
LL vs LR
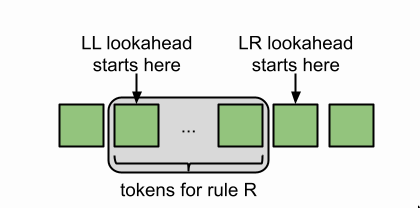
There is no LL(0) parser, LL’s need a lookahead.
LR parsers(LR(0)) can do without a lookahead because LR’s lookahead starts from the back and it gets to see all of the rule’s tokens.
Since LR lookahead starts from the end of a rule, a LR(1) parser has strictly more information available to it when making a decision than an LL(1) parser.